
The durable execution stack for agents

People trust agents waaay too much.
Nobody acknowledges that they’re really frail abstractions on top of a stack that was never intended to support them.
Claude is down all the time
You can’t deterministically define retries in non-deterministic workflows
Agents don’t have awareness of services’ or tools’ states, or awareness of the data
LLMs start going off-track during longer processes
So if you want agents in production, you need to make sure that all the abstraction layers below it can and know how to handle failures. These include infrastructure, agent execution, and the semantic layer.
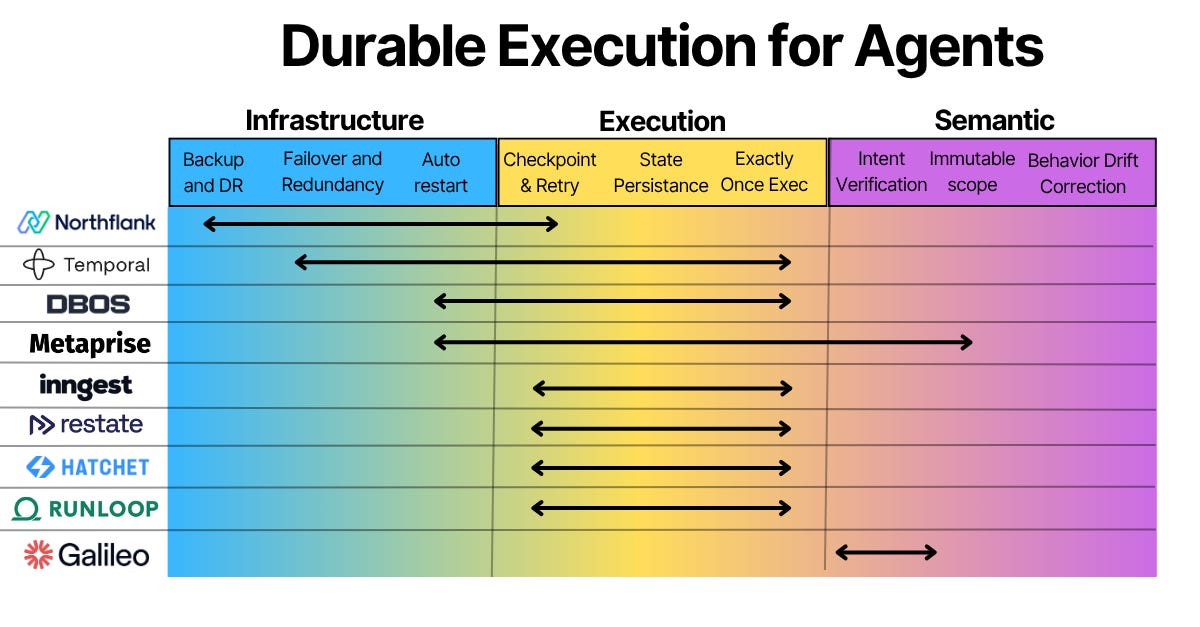
Infrastructure Durability
This include the all-purpose compute durability like backup and disaster recovery, high availability and redundancy, auto restarts and self healing.
The key here is that you need application-level awareness to resume agents. If you simply re-start a container but the application does not know to run again, you’re not doing much.
The two solutions that I found here include:
Northflank - these guys do HA infrastructure provisioning, and also offer stateful sandboxes for agents. They can be used as a infrastructure reliability platforms for other agent execution environments. It runs the containers, manages the database, provides persistent storage, handles networking, BYOC, and keeps everything alive.
Temporal - they described it very well here: “Workflow code is deterministic, [while] your AI Agent can absolutely make decisions based on non-deterministic LLM outcomes.” It guarantees exactly-once execution, replays workflows after failure, and records every agent decision.
Agent execution
Agents (i.e. the thing running code and commands written by an LLM) can hiccup in a lot of ways. For example, it may hit a rate limit from the LLM provider, or a request times out.
This layer would make sure that
Agent tasks get executed and completed steps are stored
If interrupted they start again from the same point
They get executed once, no duplicates
They coordinate across time to wait for job completions, schedules and such
Can go back and try again if output is not validated
A good selection of tools here include
DBOS - durable execution as a library that checkpoints agent workflows directly into a Postgres database, recovering from the last completed step with no separate orchestration server required.
Restate - journal-based durable execution for distributed services, where every step is persisted before it proceeds so agents resume exactly where they stopped regardless of which worker picks up the work.
Inngest - step-level memoization (yes this is the spelling) that stores each result externally and re-injects it on retry, making agent workflows crash-proof without requiring a new infrastructure layer.
Hatchet - managed task queue with retry policies and real-time visibility into agent job execution
Runloop - microVM-isolated developer environments purpose-built for AI agents, with snapshot and resume so agents can suspend mid-task and pick up exactly where they left off.
Semantic Analysis
LLMs drift by design, and simply saying “pls don’t drift” or spinning up an orchestrator agent and asking it “pls don’t drift” won’t help.
You will end up with agents not completing the assigned task, doing something else, reporting complete on an incomplete job, or just hallucinating results.
There’s a lot of work here in security to prevent against injections and confused deputy, but I have not seen to much work in preventing non-malicious drift.
So far, I’ve seen
Galileo’s evals for
Agent Flow -A binary evaluation metric that measures the correctness and coherence of an agentic trajectory
Intent Change - Measures shift in the user’s primary conversational goal or workflow during a session, relative to their initial stated intent.
Action Advancement - Measures how effectively each action advances toward the goal.
Action Completion - Determines whether the agent successfully accomplished all of the user’s goals.
Metaprise’s solutions that go across execution into semantic intent and consist of:
Mission Layer - Mission transitions through exactly 8 deterministic states. Each transition is validated by the Control Plane, recorded in the AuditChain, and visible in real-time via Observability. No state can be skipped; no transition can be forced.
AURA runtime - Every execution step is recorded as an event. If the runtime crashes - hardware failure, network partition, OOM kill - the Durable Execution Engine replays the event history to recover exact state. The agent resumes from where it stopped, not from the beginning.
Worth noting that Metaprise pivoted into AI agents after a few years in the fintech space, which is clearly more understandable than pivoting to AI from shoes.
What next?
I would love to see some of that semantic analysis more developed to the point where you can correct behavior drift at runtime (because you won’t fix it if you use LLMs for “reasoning”) and implement that in the agent execution layer.