
LLM Deployment Gotchas (for SecOps but not just)

You used to deploy a product. Now, you deploy a product and an LLM. But the LLM is not part of the product. So what do we do?
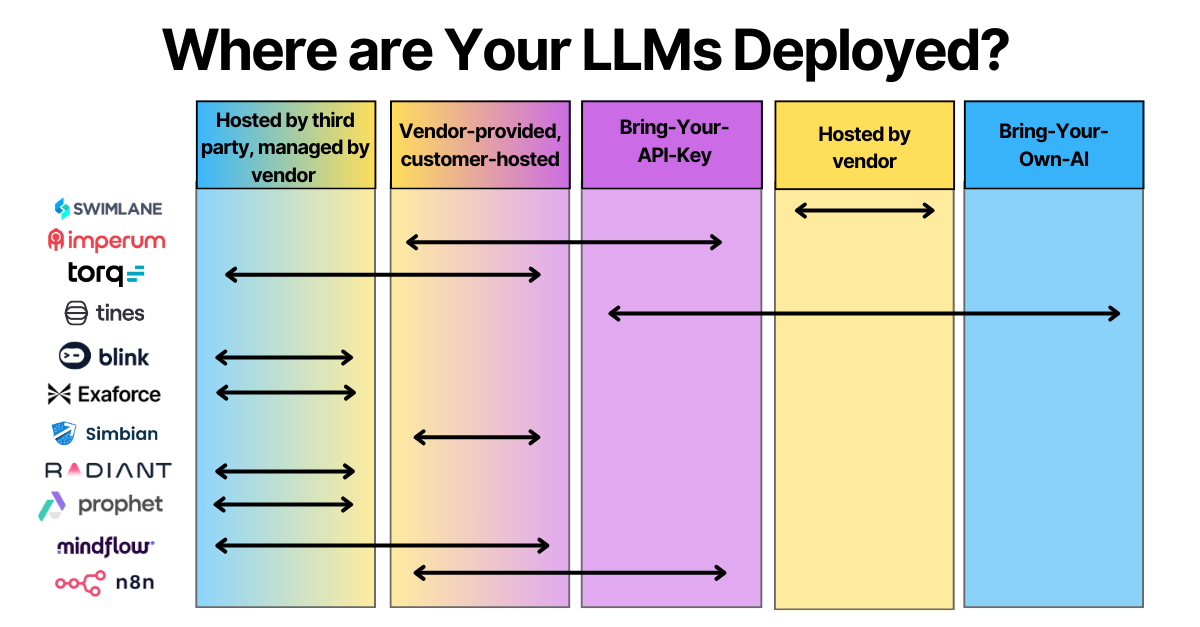
I don’t know, but we must first recognize how products actually deploy and manage their LLMs. These include:
AI via API - vendor calls external LLM service via an API call. Vendor manages the API keys and subsequent authorization, customer has no control over this data flow.
Bring-your-API-Key - vendor calls external LLM services via an API call. Customer brings their own API key to access the LLM.
Hosted by vendor, model runs on vendor-configured infrastructure - vendor designs and provisions their LLM infrastructure, which can be, for example, GPU clusters in a collocation environment. The customer interacts with the model in an as-a-service model.
Hosted by third party (cloud) AI provider, managed by vendor - vendor deploys and manages the model that runs on hyperscaler services such as AWS Bedrock.
Vendor-packaged, customer-hosted - vendor provides a container or VM image (like a docker compose template) for the customer to run on their preferred infrastructure.
Bring-your-own-AI - customer runs their own model independently and integrates it with the rest of the application logic, perhaps using MCP.
**Changelog**
BlinkOps Supports
✔️ Bring-your-own-AI
✔️ Bring-your-API-Key
✔️ Hosted by third party (cloud) AI provider, managed by vendor
Thanks Filip Stojkovski
Swimlane Supports:
✔️ Hosted by vendor
✔️ Bring-your-own-AI
✔️ Bring-your-API-Key
Thanks Cody Cornell
Exaforce Supports:
✔️Vendor-packaged, customer-hosted
✔️Hosted by vendor
Thanks Taylor Smith
Prophet Security
✔️ Bring-your-API-Key
✔️ Hosted by third party (cloud) AI provider, managed by vendor
✔️Vendor-packaged, customer-hosted
Thanks Augusto Barros
**
AI via API
I don’t have any SecOps examples for this (which is a good thing), but most products with AI features just send your request in a JSON payload to ChatGPT.
Bring-your-API-Key
Tines - customers can plug in their own licensed model from providers such as OpenAI, Azure, Anthropic, Google.
Imperum’s models-as-a-service need customers to supply API keys and model names, and inference flows through our unified endpoints.
Hosted by vendor
The Swimlane LLM is hosted in Turbine Cloud and managed by Swimlane. On-premises customers connect to this cloud instance for AI features.
Tines runs models within Tines’ cloud infrastructure and do not involve networking over the public Internet to third party providers.
Hosted by third party, managed by vendor
Prophet AI leverages hosted LLMs supplied by Microsoft Azure OpenAI. The deployment and usage of these models are managed in-house by Prophet Security.
Torq can manages its LLM capabilities which are hosted in the cloud using services from OpenAI and Google Gemini.
Radiant privately hosts all LLMs used in production, including both Azure OpenAI and LLaMA models. Inference runs in isolated environments.
Mindflow manages their own models, which are deployed in a dedicated AWS account using AWS Bedrock.
BlinkOps manages the models and their selection, optimizing for the specific task (workflow generation vs. agent reasoning vs. case analysis).
Exaforce’s multi-model AI engine is built and deployed in AWS Bedrock.
Vendor-packaged, customer-hosted
n8n’s Self-hosted AI Starter Kit is an open, docker compose template that bootstraps a fully featured Local AI and Low Code development environment. Curated by n8n, it combines the self-hosted n8n platform with a list of compatible AI products, including Ollama, Qdrant, and PostgreSQL
Imperum allows customer to install inference service inside your own datacenter. by providing installers and configuration scripts. Inference runs via llama.cpp on any Linux server.
Mindflow’s model can also be deployed directly within the customer’s own AWS account to align with their internal security and compliance policies.
Simbian - offers a public or private cloud image that can be hosted by the customer in their air-gapped environment.
Torq offers modular options for hosting large language models, such as on the customer’s private cloud or instance.
Bring-your-own-AI
Tines - customers can configure networking to their own self-hosted model, including on-premise or cloud, navigating through proxies etc, as required