
How to evaluate intent without using LLMs recursively

You’ll see more vendors claiming they evaluate Agent intent. How? They ask another agent to evaluate it. But if LLMs could catch hallucinations or injections…
They wouldn’t hallucinate in the first place!
“But we use a rubric” or “but our agent is fine-tuned” are not fixes.
And so I embarked into a 30 hour journey to find non-LLM ways of evaluating agent intent. Or at the very least perform the analysis such that an LLM would only be used to convert it into natural language.
Intent is useful for both security and checking whether agent is being stupid.
But I don’t want to differentiate between the two for now. Let’s treat intent as a general capability, and let’s find some non-recursive ways of determining an Agent’s intent.
I found three ways in which you can do it:
Using reference answers - useful when you know what the agent must do. Not useful if you want self-determining agents
Without using reference answers - useful for self-determining agents, very hard to do, which is why everybody defaults to using LLM-as-judges
Learning-based techniques - where you don’t have reference answers so you look at actual agent behaviors, their outcomes, and defining references based on that
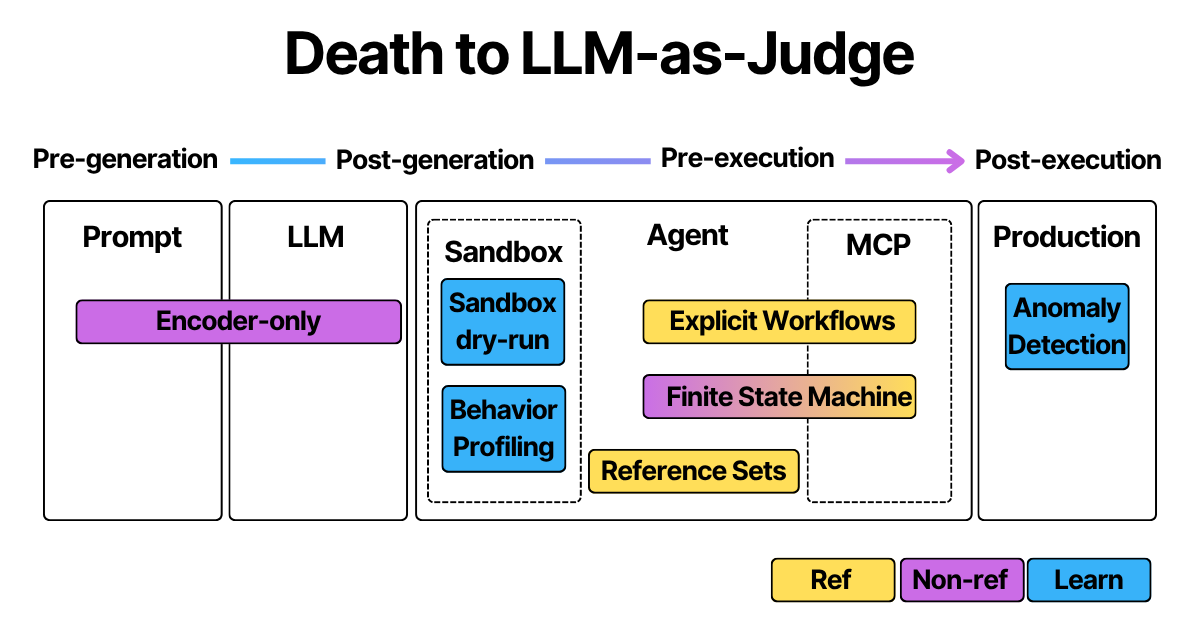
Category 1: Reference-Based Techniques
You already know what the agent is supposed to do. Intent evaluation is a continuous comparison: is what the agent is doing consistent with what was defined?
Explicit Workflows
When you define a policy, you restrict the actions and tools available. But policy only makes sure that agents don’t do what they’re not supposed to. They will not not evaluate whether the agent is doing what it is supposed to
So instead of a destructive approach, you must take a constructive approach. You have to explicitly define:
What tools the agent has available
What are the steps through which it must cycle through
What data sources it may access.
Whether it can spawn sub-agents
What API endpoints it can call using what methods
Prompting an agent to use tool X in scenario Y does not classify as an explicit definition. Using an LLM to route a workflow to a deterministic tool call does classify as an explicit definition.
You have to build this into your agents from the ground up. Only then can you evaluate the intent (deterministically) with checks such as: did this step execute? Are the fields filled in correctly? Did the API call return a 200 code? Was the data retrieved via API validated?
Reference Sets
MITRE ATLAS as a Security Reference Set
For security cases, intent evaluates whether an agent behaves how the owner wants, and not how an attacker wants. You can use MITRE ATLAS as a pre-built reference taxonomy of adversarial techniques mapped to observable behaviors.
You can map agent actions to ATLAS techniques and flag matches.
Take AML.T0053 (AI Agent Tool Invocation) as a prime example. Because agents are connected to external services via Model Context Protocol (MCP) servers or custom APIs, an attacker doesn’t need a traditional system exploit; they just need to hijack the agent’s existing agency.
A real-world attack chain utilizing this technique can like this:
Initial Access / Context Poisoning: The agent reads an untrusted, public slack thread or web page containing an indirect prompt injection payload.
Execution / Tool Abuse: The injected instruction overrides the agent’s system prompt, coercing the LLM to invoke an integrated service it shouldn’t touch in this context—for example, calling a
database_querytool with a malicious SQL command or spinning up a shell tool.Exfiltration: The agent executes the tool, harvests the data, and pipes it back out to an attacker-controlled endpoint.
And yes, this is a place where using an LLM to compare your agent’s behavior with ATLAS is an acceptable use case. If you are passing your agent’s historical trace to an LLM-as-a-judge specifically tasked with doing taxonomic matching against ATLAS, you aren’t asking the LLM to define “bad behavior” on the fly. You are using it as a fuzzy compiler to map raw runtime behaviors to deterministic threat categories.
Agent Fault taxonomies
While I haven’t found anything comparable to MITRE ATLAS for general “dumb agent” patterns, I found a study where the most common failures were documented. These include:
Dependency and Integration Changes
Data and Type Mismatch
LLM Behaviour and Interface Changes
State and Control Complexity
External API and Tool Changes
Weak Error Handling and Logging
[etc]
I expect that over time, most agents will behave fairly similar regardless of the environment they live in. This means that we can have a reference for common agent failure patterns and compare against that.
Category 2: Not Reference-Based Techniques
No predetermined correct behavior. Intent is inferred from the signal properties of the input, output, or action itself.
Encoder-Only Classifier
You don’t need Charles Dickens to write a narrative on whether the agent forgot to pull a document and made up some numbers.
A simple Y/N is fine.
So you can use encoder-only models. They process text but don’t generate it. They apply full bidirectional attention over the entire input, they capture token interdependencies better than decoder-only LLMs.
Some vendors train or fine-tune a BERT-family model (DeBERTa, RoBERTa, ModernBERT) on labeled examples of aligned vs. misaligned, or benign vs. malicious, inputs. The model outputs a scalar (0.0–1.0) against a threshold you define.
Finite State Machine-Based Semantic Parsing
I highly recommend Akash Mandal’s article on this.
A finite state machine (FSM) is defined over the semantic space of valid agent actions, namely states representing tool call types and transitions representing allowable sequences.
At runtime, the observed action sequence is parsed through the FSM. States outside the machine are violations; unexpected transitions are anomalies.
The FSM first evaluates stream-by-stream intent by checking if the agent’s real-time network behavior conforms to a valid syntactic state machine. The FSM defines a strict mathematical boundary of what the agent is allowed to do next based on its current state.
If the agent is in a CHAT_REQUEST state and suddenly attempts to stream data to an unconfigured external IP address without transitioning through an approved tool-use state, the FSM hits an undefined transition.
While a single anomalous transition can be indicative of intent drift or some malicious dark forces, you may still have individually valid activities that can only be determined anomalous when they constitute a chain.
Category 3: Learning-Based Techniques
The system learns what normal looks like from observed behavior. Deviations signal potential intent misalignment.
Sandbox - Behavioral Profiling and Dry Runs
Run the agent in a controlled environment and observe what it actually does: which tools it calls, what data volumes it handles, what external destinations it reaches, what system calls it makes.
Once you have the data, you can either:
Graduate the actions into production (perhaps even deterministically rather than invoking another production Agent)
Use that observed profile as the reference for defining least-privilege permissions, just-in-time access controls, deviation alerting. The bad part is that the agent can behave differently in production than it did in the sandbox.
Anomaly Detection on Tool Call Patterns
Sits as an active, inline telemetry monitor on your orchestration thread. It flags anomalies like recursive loops (e.g., the agent calling the same tool 15 times with minor argument variations), severe token count spikes, or out-of-order tool executions that violate basic programmatic workflows. It acts as an operational circuit breaker, killing the agent's execution loop before an infinite loop racks up a massive API bill or floods downstream systems.